
Span
tl;dr Use Span
Contents
Introduction
C# gives us great flexibility when it comes to using different kinds of memory. But the majority of the developers use only the managed one. Let’s take a brief look at what C# has to offer for us:
- Stack memory - allocated on the Stack with the
stackallockeyword. Very fast allocation and deallocation. The size of the Stack is very small (usually < 1 MB) and fits well into CPU cache. But when you try to allocate more, you getStackOverflowExceptionwhich can not be handled and immediately kills the entire process. Usage is also limited by the very short lifetime of the stack - when the method ends, the stack gets unwinded together with its memory. Stackalloc is commonly used for short operations that must not allocate any managed memory. An example is very fast logging of ETW events in corefx: it has to be as fast as possible and needs very little of memory (so the size limitation is not a problem).
internal unsafe void BufferRented(int bufferId, int bufferSize, int poolId, int bucketId)
{
EventData* payload = stackalloc EventData[4];
payload[0].Size = sizeof(int);
payload[0].DataPointer = ((IntPtr)(&bufferId));
payload[1].Size = sizeof(int);
payload[1].DataPointer = ((IntPtr)(&bufferSize));
payload[2].Size = sizeof(int);
payload[2].DataPointer = ((IntPtr)(&poolId));
payload[3].Size = sizeof(int);
payload[3].DataPointer = ((IntPtr)(&bucketId));
WriteEventCore(1, 4, payload);
}
- Unmanaged memory - allocated on the unmanaged heap (invisible to GC) by calling
Marshal.AllocHGlobalorMarshal.AllocCoTaskMemmethods. This memory must be released by the developer with an explicit call toMarshal.FreeHGlobalorMarshal.FreeCoTaskMem. By using it we don’t add any extra pressure for the GC. It’s most commonly used to avoid GC in scenarios where you would normally allocate huge arrays of value types without pointers. Here you can see some real-life use cases from Kestrel. - Managed memory - We can allocate it with the
newoperator. It’s called managed because it’s managed by the Garbage Collector (GC). GC decides when to free the memory, the developer doesn’t need to worry about it. As described in one of my previous blog posts, the GC divides managed objects into two categories:- Small objects (
size < 85 000 bytes) - allocated in the generational part of the managed heap. The allocation of small objects is fast. When they are promoted to older generations, their memory is usually being copied. The deallocation is non-deterministic and blocking. Short-lived objects are cleaned up in the very fast Gen 0 (or Gen 1) collection. The long living ones are subject of the Gen 2 collection, which usually is very time-consuming. - Large objects (
size >= 85 000 bytes) - allocated in the Large Object Heap (LOH). Managed with the free list algorithm, which offers slower allocation and can lead to memory fragmentation. The advantage is that large objects are by default never copied. This behavior can be changed on demand. LOH has very expensive deallocation (Full GC) which can be minimized by using ArrayPool.
- Small objects (
Note: When I say that given GC operation is slow I don’t mean that the .NET GC is slow. .NET has a great GC, but No GC is better than any GC.
The Problem
When was the last time you have seen a public .NET API that was accepting pointers? During my recent NDC Oslo talk, I have asked the audience who has ever used stackalloc. One person (Kristian) from more than one hundred has raised the hand. Why is it so uncommon to use the native memory in C#?
Let’s try to answer this question by designing an API for parsing integers for all kinds of memory.
We start with a string which is a managed representation of buffer of characters.
int Parse(string managedMemory); // allows us to parse the whole string
What if we want to parse only selected part of the string?
int Parse(string managedMemory, int startIndex, int length); // allows us to parse part of the string
Ok, so let’s support the unmanaged memory now:
unsafe int Parse(char* pointerToUnmanagedMemory, int length); // allows us to parse characters stored on the unmanaged heap / stack
unsafe int Parse(char* pointerToUnmanagedMemory, int startIndex, int length); // allows us to parse part of the characters stored on the unmanaged heap / stack
It’s already four overloads and I am pretty sure that I have missed something ;)
Now let’s design an API for copying blocks of memory:
void Copy<T>(T[] source, T[] destination);
void Copy<T>(T[] source, int sourceStartIndex, T[] destination, int destinationStartIndex, int elementsCount);
unsafe void Copy<T>(void* source, void* destination, int elementsCount);
unsafe void Copy<T>(void* source, int sourceStartIndex, void* destination, int destinationStartIndex, int elementsCount);
unsafe void Copy<T>(void* source, int sourceLength, T[] destination);
unsafe void Copy<T>(void* source, int sourceStartIndex, T[] destination, int destinationStartIndex, int elementsCount);
Update: We don’t need to worry about handling long parameters. The Array in .NET has a method GetLongLength but it never returns value bigger than int.Max.
As you can see supporting any kind of memory was previously hard and problematic.
Span is the Solution
Span<T> (previously called Slice) is a simple value type that allows us to work with any kind of contiguous memory:
- Unmanaged memory buffers
- Arrays and subarrays
- Strings and substrings
It ensures memory and type safety and has almost no overhead.
Prerequisites
To work with Span you need to install the latest System.Memory NuGet package and set LangVersion to C# 7.2 or newer.
<PropertyGroup>
<LangVersion>7.2</LangVersion>
</PropertyGroup>
Note: Older compilers might give you errors like this:
Error CS8107 Feature 'ref structs' is not available in C# 7.0. Please use language version 7.2 or greater.
Using Span
I would say that you can think of it like of an array, which does all the pointer arithmetic for you, but internally can point to any kind of memory.
We can create Span<T> for unmanaged memory:
Span<byte> stackMemory = stackalloc byte[256]; // C# 7.2
IntPtr unmanagedHandle = Marshal.AllocHGlobal(256);
Span<byte> unmanaged = new Span<byte>(unmanagedHandle.ToPointer(), 256);
Marshal.FreeHGlobal(unmanagedHandle);
There is even implicit cast operator from T[] to Span<T>:
char[] array = new char[] { 'i', 'm', 'p', 'l', 'i', 'c', 'i', 't' };
Span<char> fromArray = array; // implicit cast
There is also ReadOnlySpan<T> which can be used to work with strings or other immutable types.
ReadOnlySpan<char> fromString = "Strings in .NET are immutable".AsSpan();
Once you create it, you can use it in a way you would typically use an array - it has a Length property and an [indexer], which allows to get and set the values.
The simplified API (full can be found here):
Span(T[] array);
Span(T[] array, int startIndex);
Span(T[] array, int startIndex, int length);
unsafe Span(void* memory, int length);
int Length { get; }
ref T this[int index] { get; set; }
Span<T> Slice(int start);
Span<T> Slice(int start, int length);
void Clear();
void Fill(T value);
void CopyTo(Span<T> destination);
bool TryCopyTo(Span<T> destination);
API Simplicity
Let’s redesign parsing and copying APIs mentioned earlier and take advantage of Span<T>:
int Parse(ReadOnlySpan<char> anyMemory);
int Copy<T>(ReadOnlySpan<T> source, Span<T> destination);
As simple as it gets! Span abstracts almost everything about memory. It makes using the unmanaged memory much easier both for APIs producers and consumers.
How does it work?
There are two versions of Span:
- For the runtimes existing prior to Span.
- For the new runtimes, which implement native support for Spans.
The version for the existing runtimes is implemented in corefx. .NET Core 2.0 is so far the only runtime that implements native support for Span.
The Span for existing Runtimes consists of three fields: reference (represented by simple reference type field), byteOffset (IntPtr) and length (int, not long). When we access n-th value, the indexer does the pointer arithmetic for us (pseudocode):
ref T this[int index]
{
get => ref ((ref reference + byteOffset) + index * sizeOf(T));
}
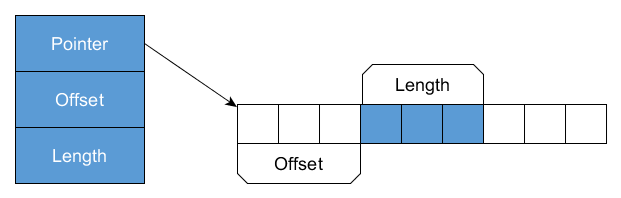
The new GC knows how to deal with Span, the reference and byteOffset fields got merged into an interior pointer. New GC is aware of the fact that it’s merged reference and it has the native support for updating this reference when it’s needed during the Compact phase of the garbage collection (when the underlying object like array is moved, the reference needs to be updated, the offset needs to remain untouched).
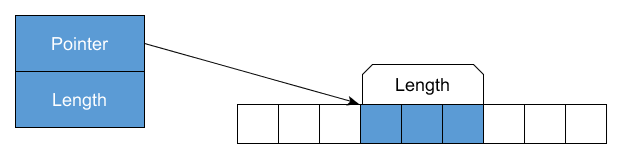
IL and C# do not support ref T fields. .NET Core 2.0+ implements it by representing it via ByReference type, which is just a JIT intrinsic.
Performance
Slicing without managed heap allocations!
Slicing (taking part of some memory) is core feature of Span. It does not copy any memory, it simply creates Span with different pointer and length (and offset for the old runtimes).
Why is it so important? Because so far in .NET anytime we wanted to substring a string the .NET was allocating new string for us and copying the desired content to it. Pseudocode:
string Substring(string text, int startIndex, int length)
{
string result = new string(length); // ALLOCATION!
Memory.Copy(source: text, destinaiton: result, startIndex, length); // COPYING MEMORY
return result;
}
With Span, there is no allocation! Pseudocode:
ReadOnlySpan<char> Slice(string text, int startIndex, int length)
=> new ReadOnlySpan<char>(
ref text[0] + (startIndex * sizeof(char)),
length);
Let’s measure the difference with BenchmarkDotNet:
[MemoryDiagnoser]
[Config(typeof(DontForceGcCollectionsConfig))]
public class SubstringVsSubslice
{
private string Text;
[Params(10, 1000)]
public int CharactersCount { get; set; }
[GlobalSetup]
public void Setup() => Text = new string(Enumerable.Repeat('a', CharactersCount).ToArray());
[Benchmark]
public string Substring() => Text.Substring(0, Text.Length / 2);
[Benchmark(Baseline = true)]
public ReadOnlySpan<char> Slice() => Text.AsSpan().Slice(0, Text.Length / 2);
}
BenchmarkDotNet=v0.10.8, OS=Windows 10 Redstone 1 (10.0.14393)
Processor=Intel Core i7-6600U CPU 2.60GHz (Skylake), ProcessorCount=4
Frequency=2742189 Hz, Resolution=364.6722 ns, Timer=TSC
[Host] : Clr 4.0.30319.42000, 64bit RyuJIT-v4.7.2053.0
Job-NJYLUU : Clr 4.0.30319.42000, 64bit RyuJIT-v4.7.2053.0
Force=False
| Method | CharactersCount | Mean | StdDev | Scaled | Gen 0 | Allocated |
|---|---|---|---|---|---|---|
| Substring | 10 | 8.277 ns | 0.1938 ns | 4.54 | 0.0191 | 40 B |
| Slice | 10 | 1.822 ns | 0.0383 ns | 1.00 | - | 0 B |
| Substring | 1000 | 85.518 ns | 1.3474 ns | 47.22 | 0.4919 | 1032 B |
| Slice | 1000 | 1.811 ns | 0.0205 ns | 1.00 | - | 0 B |
It’s clear that:
- Slicing does not allocate any managed heap memory. Substring allocates. (Allocated column)
- Slicing is much faster (Mean column)
- Slicing has constant cost! Look at the values for Standard Deviation and Mean for CharactersCount = 10 and 1000!
Slow vs Fast Span
Some people call the 3-field Span “slow Span” and the 2-field “fast Span”. BenchmarkDotNet allows running same benchmark for multiple runtimes. Let’s use it and compare the indexer for .NET 4.6, .NET Core 1.1 and .NET Core 2.0.
[Config(typeof(MultipleRuntimesConfig))]
public class SpanIndexer
{
protected const int Loops = 100;
protected const int Count = 1000;
protected byte[] arrayField;
[GlobalSetup]
public void Setup() => arrayField = Enumerable.Repeat(1, Count).Select((val, index) => (byte)index).ToArray();
[Benchmark(OperationsPerInvoke = Loops * Count)]
public byte SpanIndexer_Get()
{
Span<byte> local = arrayField; // implicit cast to Span, we can't have Span as a field!
byte result = 0;
for (int _ = 0; _ < Loops; _++)
{
for (int j = 0; j < local.Length; j++)
{
result = local[j];
}
}
return result;
}
[Benchmark(OperationsPerInvoke = Loops * Count)]
public void SpanIndexer_Set()
{
Span<byte> local = arrayField; // implicit cast to Span, we can't have Span as a field!
for (int _ = 0; _ < Loops; _++)
{
for (int j = 0; j < local.Length; j++)
{
local[j] = byte.MaxValue;
}
}
}
}
public class MultipleRuntimesConfig : ManualConfig
{
public MultipleRuntimesConfig()
{
Add(Job.Default
.With(CsProjClassicNetToolchain.Net46) // Span NOT supported by Runtime
.WithId(".NET 4.6"));
Add(Job.Default
.With(CsProjCoreToolchain.NetCoreApp11) // Span NOT supported by Runtime
.WithId(".NET Core 1.1"));
Add(Job.Default
.With(CsProjCoreToolchain.NetCoreApp20) // Span SUPPORTED by Runtime
.WithId(".NET Core 2.0"));
}
}
BenchmarkDotNet=v0.10.8, OS=Windows 10 Redstone 1 (10.0.14393)
Processor=Intel Core i7-6600U CPU 2.60GHz (Skylake), ProcessorCount=4
Frequency=2742189 Hz, Resolution=364.6722 ns, Timer=TSC
[Host] : Clr 4.0.30319.42000, 64bit RyuJIT-v4.7.2053.0
.NET 4.6 : Clr 4.0.30319.42000, 64bit RyuJIT-v4.7.2053.0
.NET Core 1.1 : .NET Core 4.6.25211.01, 64bit RyuJIT
.NET Core 2.0 : .NET Core 4.6.25302.01, 64bit RyuJIT
| Method | Job | Mean | StdDev |
|---|---|---|---|
| SpanIndexer_Get | .NET 4.6 | 0.6054 ns | 0.0007 ns |
| SpanIndexer_Get | .NET Core 1.1 | 0.6047 ns | 0.0008 ns |
| SpanIndexer_Get | .NET Core 2.0 | 0.5333 ns | 0.0006 ns |
| SpanIndexer_Set | .NET 4.6 | 0.6059 ns | 0.0007 ns |
| SpanIndexer_Set | .NET Core 1.1 | 0.6042 ns | 0.0002 ns |
| SpanIndexer_Set | .NET Core 2.0 | 0.5205 ns | 0.0003 ns |
The difference is around 12-14%. In my opinion, it proves that people should not be afraid of using the “slow” Span for existing runtimes. But there is some place for further improvement for the new runtimes! So the gap might get bigger soon.
Note: Please keep in mind that this benchmark is not perfect indexer benchmark. It relies heavily on the CPU cache. I am not sure if it is even possible to design a perfect benchmark for the indexer.
Span vs Array
When we take a look at the official requirements for Span we can find:
“Performance characteristics on par with arrays.”
Let’s measure it ;)
public class SpanVsArray_Indexer : SpanIndexer
{
[Benchmark(OperationsPerInvoke = Loops * Count)]
public byte ArrayIndexer_Get()
{
var local = arrayField;
byte result = 0;
for (int _ = 0; _ < Loops; _++)
{
for (int j = 0; j < local.Length; j++)
{
result = local[j];
}
}
return result;
}
[Benchmark(OperationsPerInvoke = Loops * Count)]
public void ArrayIndexer_Set()
{
var local = arrayField;
for (int _ = 0; _ < Loops; _++)
{
for (int j = 0; j < local.Length; j++)
{
local[j] = byte.MaxValue;
}
}
}
}
BenchmarkDotNet=v0.10.8, OS=Windows 10 Redstone 1 (10.0.14393)
Processor=Intel Core i7-6600U CPU 2.60GHz (Skylake), ProcessorCount=4
Frequency=2742189 Hz, Resolution=364.6722 ns, Timer=TSC
[Host] : Clr 4.0.30319.42000, 64bit RyuJIT-v4.7.2053.0
.NET 4.6 : Clr 4.0.30319.42000, 64bit RyuJIT-v4.7.2053.0
.NET Core 1.1 : .NET Core 4.6.25211.01, 64bit RyuJIT
.NET Core 2.0 : .NET Core 4.6.25302.01, 64bit RyuJIT
| Method | Job | Mean | StdDev |
|---|---|---|---|
| ArrayIndexer_Get | .NET 4.6 | 0.5499 ns | 0.0009 ns |
| SpanIndexer_Get | .NET 4.6 | 0.6073 ns | 0.0016 ns |
| ArrayIndexer_Get | .NET Core 1.1 | 0.5455 ns | 0.0006 ns |
| SpanIndexer_Get | .NET Core 1.1 | 0.6062 ns | 0.0008 ns |
| ArrayIndexer_Get | .NET Core 2.0 | 0.5401 ns | 0.0019 ns |
| SpanIndexer_Get | .NET Core 2.0 | 0.5357 ns | 0.0010 ns |
| ArrayIndexer_Set | .NET 4.6 | 0.5028 ns | 0.0010 ns |
| SpanIndexer_Set | .NET 4.6 | 0.6057 ns | 0.0005 ns |
| ArrayIndexer_Set | .NET Core 1.1 | 0.5074 ns | 0.0013 ns |
| SpanIndexer_Set | .NET Core 1.1 | 0.6056 ns | 0.0008 ns |
| ArrayIndexer_Set | .NET Core 2.0 | 0.5069 ns | 0.0010 ns |
| SpanIndexer_Set | .NET Core 2.0 | 0.5219 ns | 0.0005 ns |
The requirement is met only for the new runtime with native Span support, .NET Core 2.0. Personally, I don’t believe that it’s possible the existing runtimes can meet this requirement. There is no way to add some features like array bound check elimination for the existing runtimes.
The Limitations
Span supports any kind of memory. It means that is should have the same restrictions as the most demanding type of memory.
In our case, it’s stack memory. Pointer to stack must not be stored on the managed heap. When the method ends, the stack gets unwinded and the pointer becomes invalid. If we somehow store it on the heap, bad things are going to happen. Anything else that contains a pointer to stack also must not be stored on the managed heap. It means that Span must not be stored on the managed heap.
Moreover, Span as a value type with more than one field suffers from Struct Tearing. Span is supposed to be very fast, so we can not solve struct tearing issue by introducing access synchronization.
Stack-only
Span is stack-only type:
- Span instances can reside only on the Stack
- Stacks are not shared across multiple threads, so single Stack is accessed by one thread at the same time. It ensures thread safety for Span!
- Stacks are short-lived, which means that GC will track fewer pointers. If we would let them live long (on the heap), we could get to a situation where Span creates big overhead for GC.
No Heap
Because of the fact that Span is a stack-only type, it must not be stored on the heap. Which leads us to a long list of limitations.
Span must not be a field in non-stackonly type
If you make Span a field in a class it will be stored on the heap. This is prohibited!
class Impossible
{
Span<byte> field;
}
Since C# 7.2 it is be possible to have a Span field in other stack-only type.
ref struct TwoSpans<T>
{
// can have ref-like instance fields
public Span<T> first;
public Span<T> second;
}
Span must not implement any existing interface
Let’s consider following C# and IL code:
void NonConstrained<T>(IEnumerable<T> collection)
struct SomeValueType<T> : IEnumerable<T> { }
void Demo()
{
var value = new SomeValueType<int>();
NonConstrained(value);
}
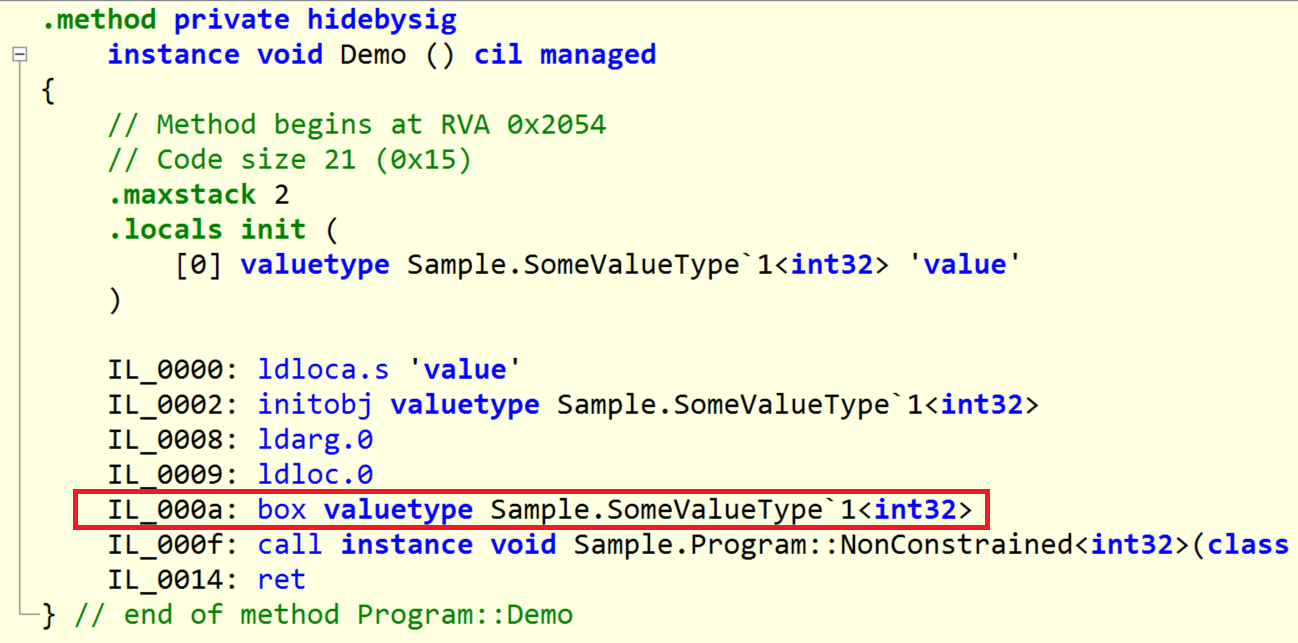
The value got boxed! Which means stored on the heap. Which is prohibited for the Span. You can read more about boxing in my previous blog post.
The point is that to prevent from boxing Span must not implement any existing interface like IEnumerable. If in the future C# allows defining an interface that can be implemented only by a struct, then it might become possible.
Span must not be a parameter for async method
async and await are awesome C# features. They make our life easier by solving a lot of problems and hiding a lot complexity from us.
But whenever async & await are used, an AsyncMethodBuilder is created. The builder creates an asynchronous state machine. Which at some point of time might put the parameters of the method on the heap. This is why Span must not be an argument for an async method.
Span must not be a generic type argument
Let’s consider following C# code:
Span<byte> Allocate() => new Span<byte>(new byte[256]);
void CallAndPrint<T>(Func<T> valueProvider) // no generic requirements for T
{
object value = valueProvider.Invoke(); // boxing!
Console.WriteLine(value.ToString());
}
void Demo()
{
Func<Span<byte>> spanProvider = Allocate;
CallAndPrint<Span<byte>>(spanProvider);
}
As you can see the non-boxing requirement can not be ensured today if we allow the Span to be generic type argument. One of the possible solutions could be to introduce new generic constraint: stackonly. But then all the managed compilers would have to respect it and ensure the lack of boxing and other restrictions. This is why it was decided to simply forbid using Span as a generic argument.
Initially, this requirement was verified at runtime by .NET Core 2.0. Since C# 7.2 it’s also enforced by the compiler at compile time.
Memory
Memory is a new type which can point only to managed memory, so it does not have stack-only limitation. It can be created out of a managed array, string or IOwnedMemory, passed to async method(s) or stored in the field of a class. When you need Span, you just call the .Span property, which creates Span on demand. Then you use it within the current scope.
public readonly struct Memory<T>
{
private readonly object _object; // String, Array or OwnedMemory
private readonly int _index;
private readonly int _length;
public Span<T> Span { get; }
public Memory<T> Slice(int start)
public Memory<T> Slice(int start, int length)
public MemoryHandle Pin()
}
Sample usage:
byte[] buffer = ArrayPool<byte>.Shared.Rent(16000 * 8); // we use an Array here, not Span
while ((bytesRead = await fileStream.ReadAsync(buffer, 0, buffer.Length)) > 0) // AWAIT! writing to array
{
ParseBlock(new ReadOnlyMemory<byte>(buffer, start: 0, length: bytesRead)); // creating ReadOnlyMemory which points to managed array
}
void ParseBlock(ReadOnlyMemory<byte> memory)
{
ReadOnlySpan<byte> slice = memory.Span; // using Span from here
}
Summary
- Allows to work with any type of memory.
- System.Memory package, C# 7.2.
- It makes working with native memory much easier.
- Simple abstraction over Pointer Arithmetic.
- Avoid allocation and copying of memory with Slicing.
- Supports .NET Standard 1.1+
- Its performance is on par with Array for new runtimes.
- It’s limited due to stack only requirements.
Sources
- Span design document
- Compile time enforcement of safety for ref-like types C# 7.2 feature description by Vladimir Sadov
- .NET Standard article by MSDN
- Span issue in coreclr repo
- Span issue in C# language repo